Introduction
In a world where a grocery receipt can reveal whether you’re expecting or how many people live in your household, privacy can no longer be treated as an inherent trait of a data point. A single fragment of information is neither sensitive nor non-sensitive on its own — its meaning depends entirely on context. Privacy Enhancing Technologies (PETs) address this dynamic view of privacy by applying obfuscation techniques that adapt to what is being asked of a dataset. These technologies hold promise not only for cross-institutional research, where both model IP and participant privacy are critical, but also for empowering individual agency over data in the emerging age of algorithms.
In 2021, I became product lead for OpenMined’s privacy infrastructure platform PyGrid (now SyftBox). My first assignment was to explore how we could make PETs — particularly Differential Privacy (DP) — more accessible to non-technical users. While PETs are powerful and flexible tools, they often demand a level of technical literacy that limits adoption. Leading a cross-disciplinary team of data scientists, privacy experts, ML engineers, and full-stack developers, we conducted a mixed-methods study to understand how users engaged with our DP features and then prototyped interface designs that explored how to lower the technical barrier to entry.
Definitions
For this use case we can define three roles:
- Data Owner - A person who controls a dataset and uses Differential Privacy (DP) to set a privacy limit that determines how much can be revealed about it.
- Data Scientist - A researcher who queries that dataset within the privacy limit using what’s called a privacy budget.
- Data Subject - An individual or entity represented by one or more data points within the dataset.
At the time, our Differential Privacy mechanism (within PySyft 0.6) allowed a Data Owner to set a privacy limit, per Data Scientist, using the method .create(budget= _) . This limit, measured in the privacy unit epsilon (ε), defined how much a Data Scientist could learn about any one Data Subject.
When a Data Scientist published a result using result.publish(sigma=_) (Figure 1.0), they could then specify how much of their privacy budget to spend — trading off privacy for accuracy through the sigma parameter — and immediately obtain results without waiting for Data Owner approval.
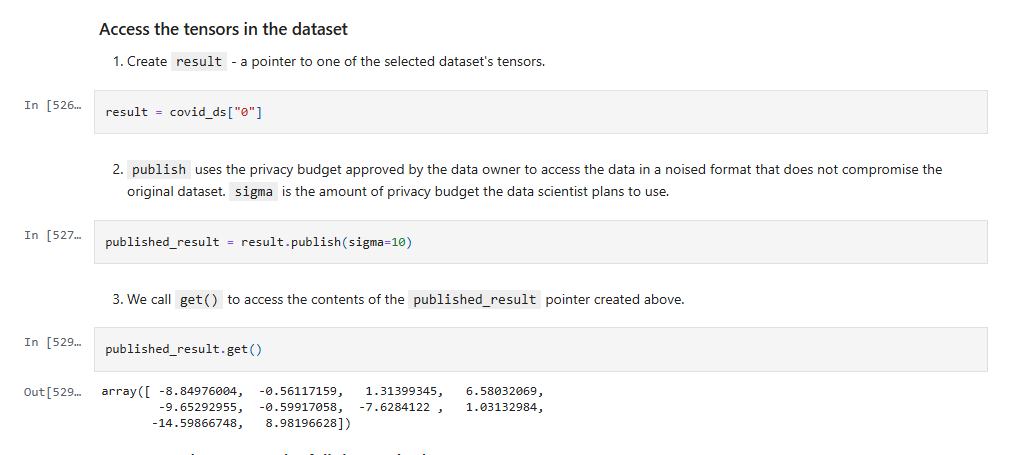
Figure 1.0 | PySyft 0.6.0 a data scientist using a privacy budget to publish a result
If a query exceeded the allocated privacy budget, the DP mechanism automatically adjusted by removing certain data subjects and injecting calibrated noise. Much like a “Where’s Waldo” puzzle, the noise concealed identifying features of any individual while preserving the usefulness of the aggregate result. Our hope was that this approach would allow Data Owners to safely open their datasets for research — reducing managerial overhead while preserving privacy.
Before beginning our user study we acknowledged that our tool, as it was, required both Data Owners and Data Scientists to have a good understanding of how risk and accuracy were tied to epsilon — a niche topic that’s usually reserved for privacy experts. Additionally, our tool required users to be proficient with Python and Jupyter Notebooks. It was clear that these limitations needed to be overcome if we were to expect a scaled use of the tool.
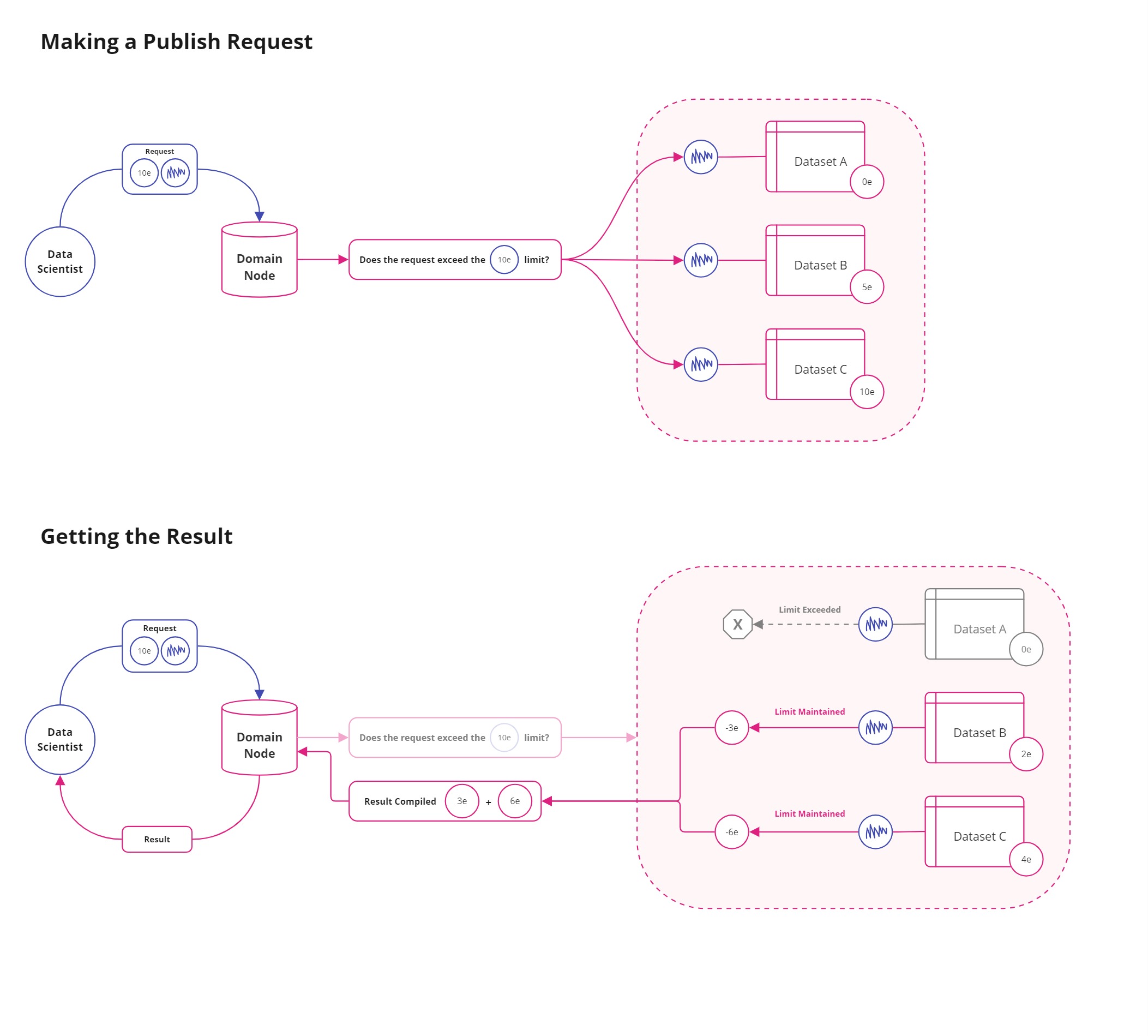
Figure 1.1 | using .publish( ) in PySyft 0.6.0
PySyft 0.6 Early Access Course
To better understand these barriers, I integrated our online course platform into a 3-week remote Early Access study (Nov 11–25, 2021). Participants were introduced to foundational PETs concepts — Remote Execution, Differential Privacy, Secure Multi-Party Computation, and Secure Enclaves — before testing PySyft’s 0.6 features through a series of interactive notebooks.
Participants progressed through the modules independently, submitting surveys and unmoderated screen recordings after each lesson. Because the features were in beta, we provided private Slack channels for bug support and accommodations such as language assistance. This setup allowed us to observe how users learned, and where they struggled, in realistic conditions.
Metrics of Understanding
Before beginning the study, we gathered baseline information to understand who was naturally drawn to PySyft and for what purposes. Participants completed a background survey covering their familiarity with PETs, PySyft, and data science. While 57% had prior exposure to PySyft and all had data science experience, the average self-reported privacy proficiency was a “2/5.”
This helped us calibrate our scenario-based assessments. After each lesson, participants were asked to:
- Complete an interactive scenario notebook, and
- Answer a short survey evaluating their confidence and comprehension.
The notebook scenarios tested whether participants could assign and request appropriate privacy budgets. The surveys evaluated how confident they felt doing so.
What we learned was striking but unsurprising:
- Participants understood how to call the functions,
- but struggled to understand the metadata required for DP to work,
- and even more so how to select an appropriate privacy budget.
We also discovered that our terminology created unintended misconceptions. The phrase “privacy budget” led participants to assume a financial metaphor — something that could be spent and recharged. In reality, privacy budget functions more like cumulative exposure: once granted, the visibility cannot be taken back. This conceptual gap had real downstream implications, especially for Data Owners who must reason about long-term privacy risk.
These findings informed immediate changes across our teams, including updates to our “Introduction to Remote Data Science” course and redesigns of our demo materials — such as a “future state” DP metadata prototype (Figure 2.0) that clarified the metadata requirements for dataset uploads.
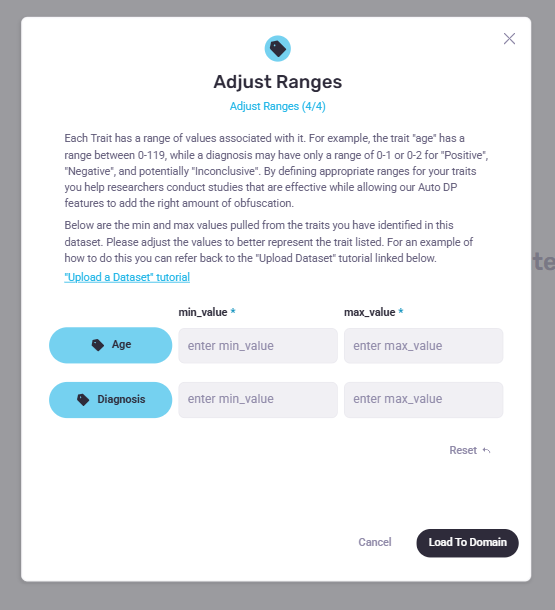
Figure 2.0 | DP metadata prototype used to explain DP metadata upon dataset upload
Conclusion
Two broader insights emerged from this Early Access study that reshaped our direction for PySyft 0.7 and beyond.
01 — Prioritize Data Management Tools
A key realization was that our product needed to shift its focus toward Data Owners and the data management experience. Only Data Owners have the full context required to understand the privacy–accuracy trade-off across an entire dataset. Yet PySyft 0.6 placed the burden on Data Scientists to request an epsilon amount — despite not being able to see the underlying data.
This misalignment led us to ask a different question: Instead of enforcing a request → release workflow, could we create a sandbox?
A sandbox model would allow Data Owners to define dataset-level privacy limits upfront, enabling Data Scientists to explore within those bounds before submitting formal study requests. This reframing fundamentally shifted how we approached governance, risk, and trust.
02 — People Learn Through Experimentation and Play
Another foundational insight: people learn DP by experimenting, not by reading formulas. Just as one cannot learn to ride a bike by reading about balance, users could not internalize the meaning of epsilon or noise injection through static explanations. They needed safe spaces to try, fail, compare, and iterate.
This shaped our subsequent design direction: building interfaces, tools, and workflows that supported tactile, exploratory learning — training wheels included.
Next Steps
This new focus on creating sandboxed experiences and more interactive interfaces led to:
- partner workshops centered around data stewardship
(see case study 2) - and the development of a differential privacy dashborad
(see case study 3)