Background
During Syft’s 0.6-0.7 development I led a research initiative exploring how privacy-enhancing technologies (PETs), such as Differential Privacy, could enable research collaboration in environments where trust was constrained by privacy concerns. Partnering with data consortia Dementias Platform UK (DPUK) and the U.S. Census Bureau’s XD Lab, I facilitated a series of workshops that mapped bottlenecks in their research pipelines and then tested new theories of governance to address those bottlenecks through speculative network diagramming. Using an ethnographic lens, my aim was to translate the institutional norms, expectations, and roles uncovered into design principles that could then be reimagined for a decentralized, privacy-aware data infrastructure. This work led to a restructure of PyGrid's roles, permissions, and policies as well as a reframed approach to how we could work with future partners.
Stakeholder Interviews
I began with stakeholder interviews across multiple organizational layers — speaking with DPUK’s director, head of IT, senior data managers, and senior scientists, as well as the xD group’s chief innovation officer, data protection officer, and researchers. These interviews helped reveal daily frictions and the unique motivators and anxieties surrounding data collaboration within each of their roles. I found that the Census Bureau, due to its inherent directive to handle data, served as a hub for other agencies which meant that a lot of their day to day frictions echoed frictions expressed by DPUK as a data consortia. Following this, I delved further into the inner-workings of data consortia. Together with technical and governance leads from DPUK, we diagramed their research pipeline — from proposal to access, approval to analysis and release, marking challenges along the way. These sessions produced shared visual artifacts (flow diagrams) that became reference points for developing a data consortium pilot.
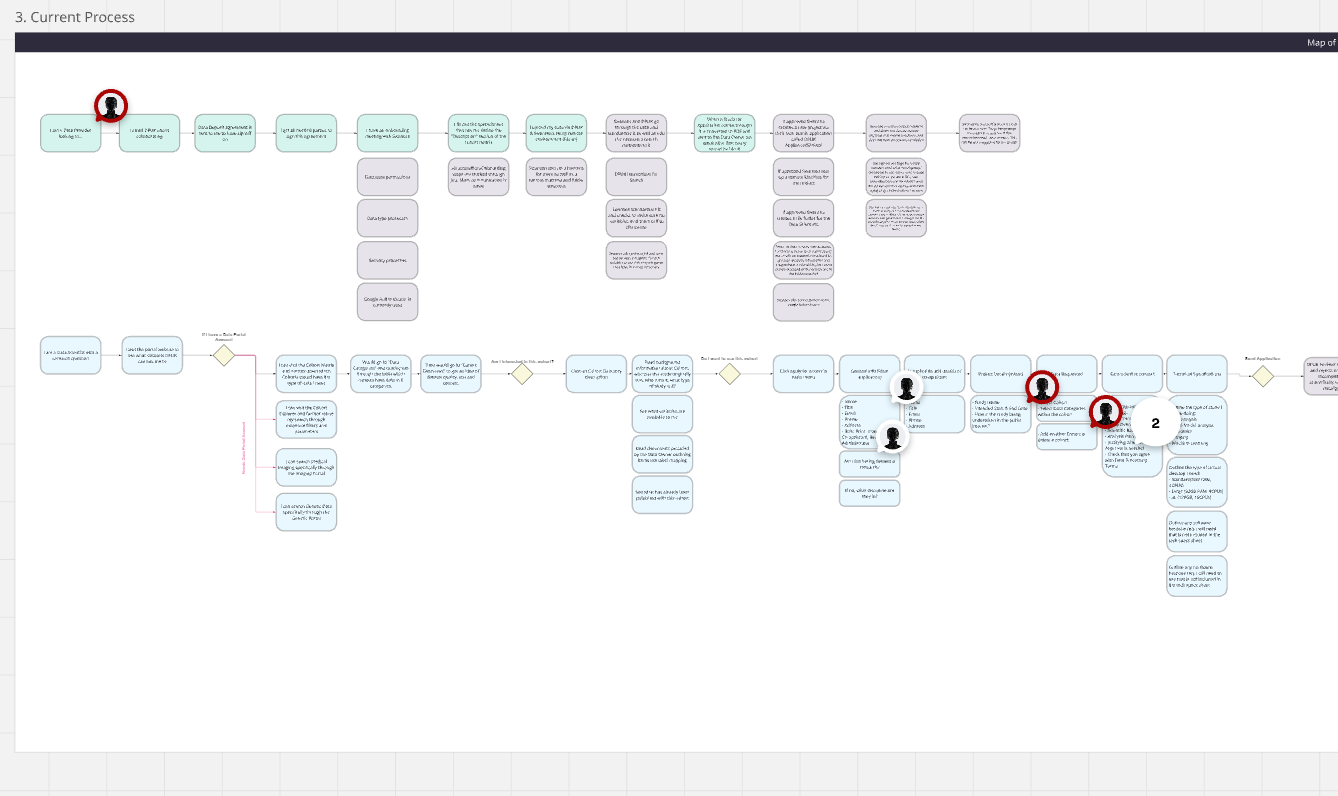
(Image: Flowchart of data pipeline, text has been obscurred to respect privacy)
Speculative Network Diagrams
Comparing insights from DPUK and Census Bureau, I developed speculative network diagrams to explore how a data consortia framework might function in a decentralized network. The proposed designs included two node types: Network Nodes (for discovery and triage) and Domain Nodes (for data management). Through co-mapping sessions with DPUK, Census Bureau, and OpenMined’s leadership we iteratively explored roles, permissions, and relationships across these nodes. These exercises formed the basis of an international trade pilot later held between Census and the UN PET Lab (2023 UN PET Guide).
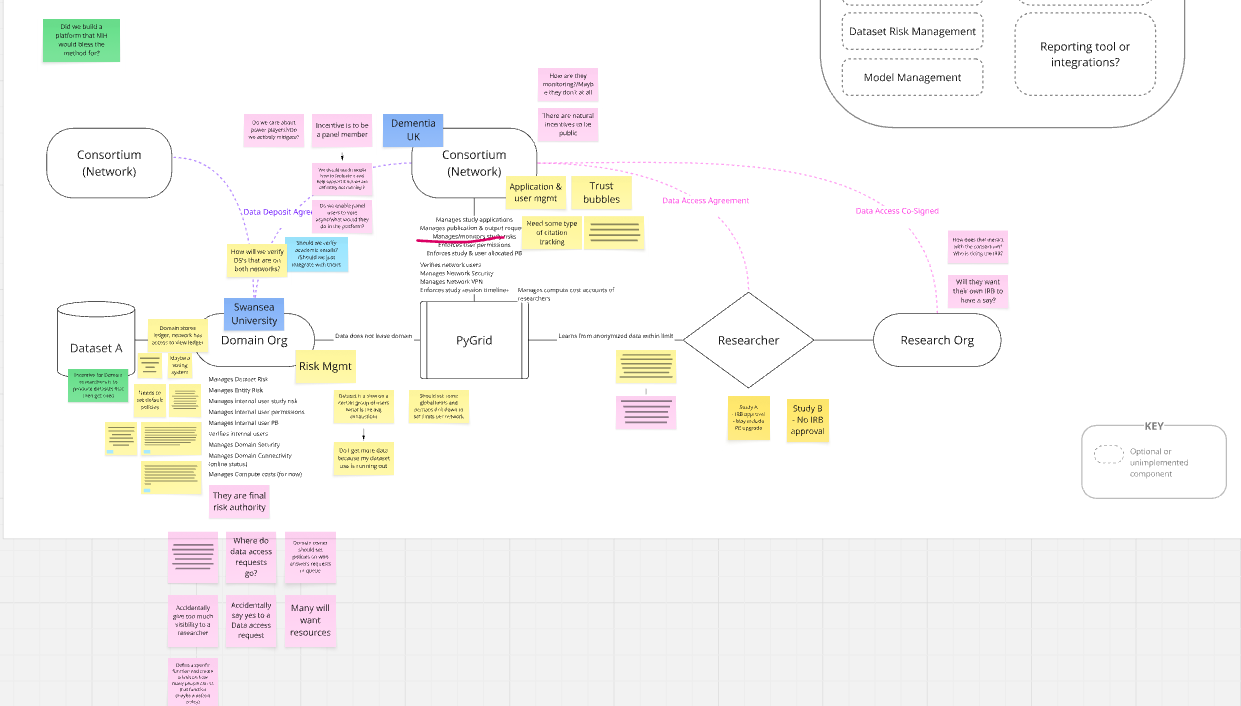
(Image: Annotated network map)
These sessions revealed that barriers to collaboration were often cultural rather than technical: unclear definitions of what a privacy breach is, differing accountability standards, and an overall mismatch between the fears that were expressed about data misuse and the policies in place to mitigate or build trust against those fears. To illustrate, many personal fears expressed about data misuse, centered on the question: who learned what, and for purpose? Yet, the data agreements used to define privacy expectations centered around where the data was being stored and analyzed from. They offered little to no guidance on how to determine if the nature of someone’s research breached privacy expectations or not.
I realized that PyGrid held a bigger promise — not just reimaging where data lived, but reimaging what metadata and computational policies could look like. A system that could help Data Owners assess who was learning from the data and for what purpose. This relational framing informed a redesign of our policies, objects, and hierarchies.
- Policies — Together with engineering we remapped what types of expectations could be translated into object policies. For example, the concern of “Who can see this object?” could be translated into visibility settings on our node and dataset objects.
- Objects — To help enforce these more contextual questions, we then mapped what metadata different objects needed to have to then trigger the policies. For example, to help answer the question “Who can learn from my data?” we mapped how a Data Owner could group users connected to their node and then enforce rules based on those groups. To illustrate, a Data Owner could now group their own research team under the user group “teammates” and then enforce a policy to allow “teammates” to write, read, and create assets within a dataset.
- Hierarchies— Perhaps one of the biggest shifts proposed, was the shift of hierarchy between “Data Requests” and “Project Objects”. In PySyft 0.6 project objects had not been created therefore “Data Requests” were the primary form of interaction between users and nodes. In 0.7 we proposed that “Project Objects” which could then hold contextual information like “Project Aim” be the primary object and take on the parent role with “Data → now Code requests” being the children. The thinking was that a project object could build a first bridge of trust before negotiating the individual queries that comprise the research study.
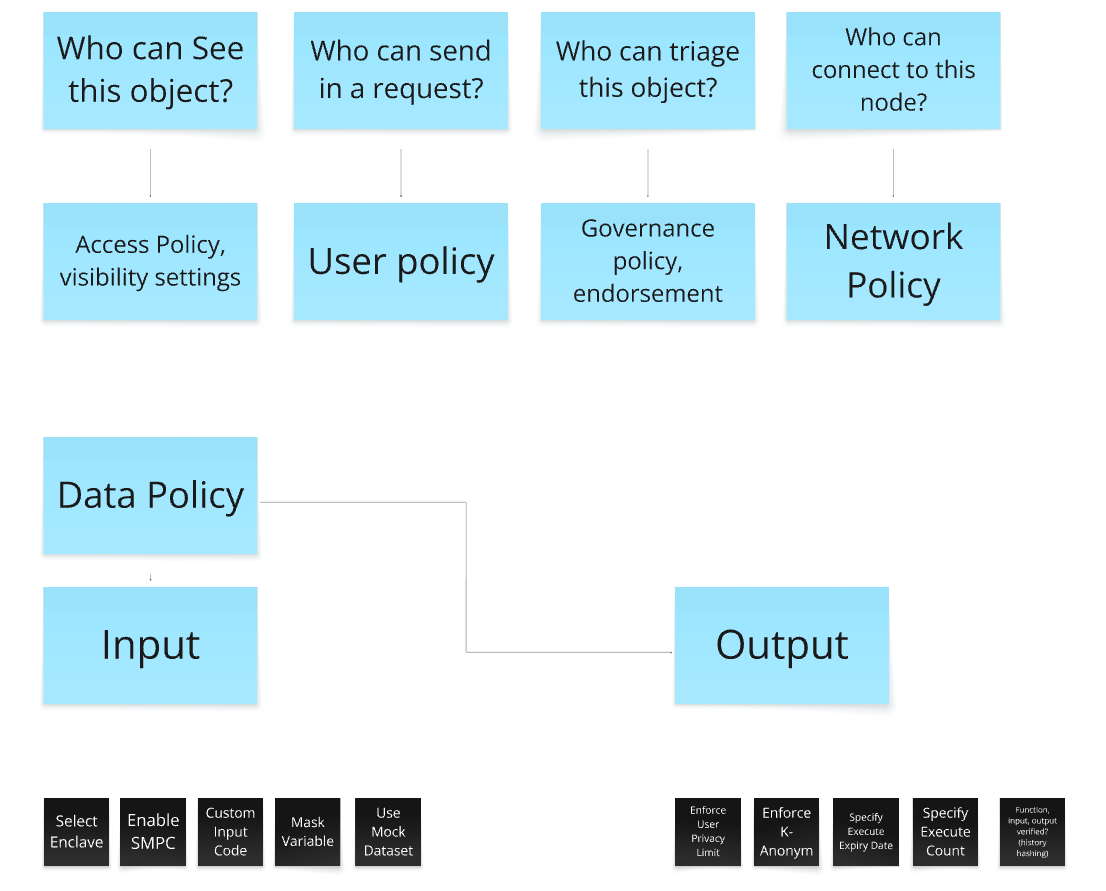
(Image: Mapping session on new policy types in PySyft 0.7.0)
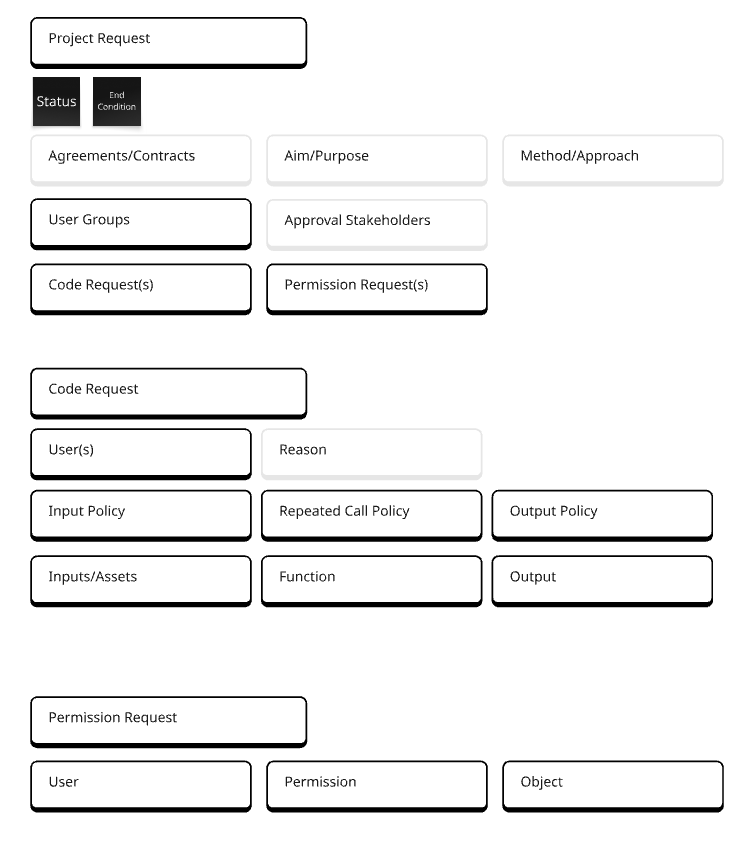
(Image: Mapping request components in PySyft 0.7.0)
Federated Networks with Decentralized Data Custody, a Mixed-Model
Although PyGrid was intended to run on a purely decentralized network setup, we realized through our discussions with DPUK and the U.S. Census Bureau that there were many government and academic use cases where a coordination layer would better reflect their internal norms and would help embedd trust via different checkpoints of verification. To maintain our system's focus on agency, while still allowing for these use cases we created a hybrid system— decentralized data custody with a new node type specifically designed for coordination.
Upon launching a PyGrid node, users could select a "node type", either "domain node" or " network node". Network nodes acted as gateway servers to other domain nodes. They were lighter weight nodes that allowed for user account creation but did not allow for dataset storage or upload. Domain nodes acted as the primary data sites and could subscribe to/ connect to network nodes in order to pass review decisions to network node members and/or inorder to make their dataset listings discoverable by network node members. Meanwhile, domain nodes in this new setup could remain autonomous. They stored research datasets, allowed for user account creation, and could connect peer to peer to other domain nodes without the need for a network node. In essence, domain nodes could do all actions while network nodes could do a subset of actions optimized for node to node connection and user management flows.
This delineation although minor in node architecture, allowed us to use nodes as a stand-in for "actors" within different information flows. With "node permissions" domain node owners could define what parameters informed their relationship with network nodes and vice versa. As in the case of DPUK, they could launch a network node to help with dataset discovery and user management, while their different cohorts could launch domain nodes and through a combination of "node permissions" and "dataset permissions" could decide which datasets then get listed under DPUK's platform.
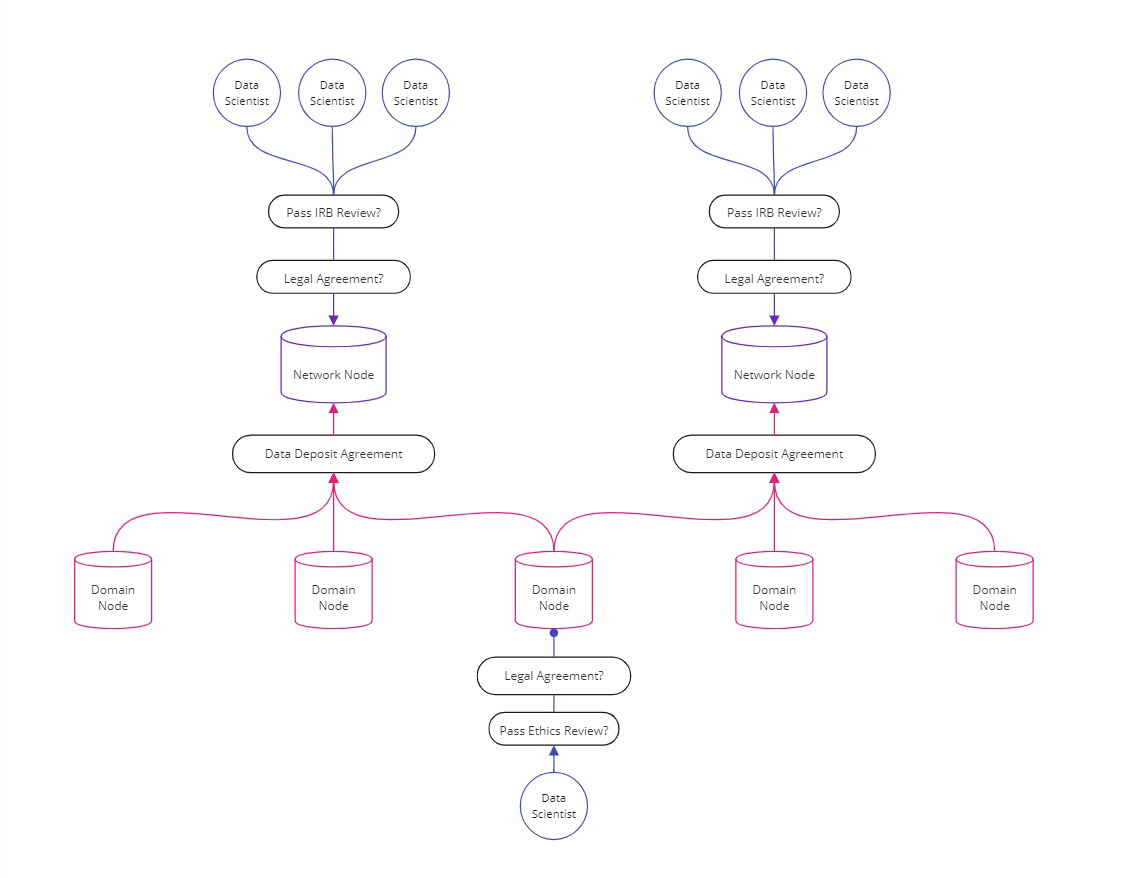
(Image: Mapping FDN network flow in PyGrid 0.7.0, a single domain node can connect to multiple networks.)
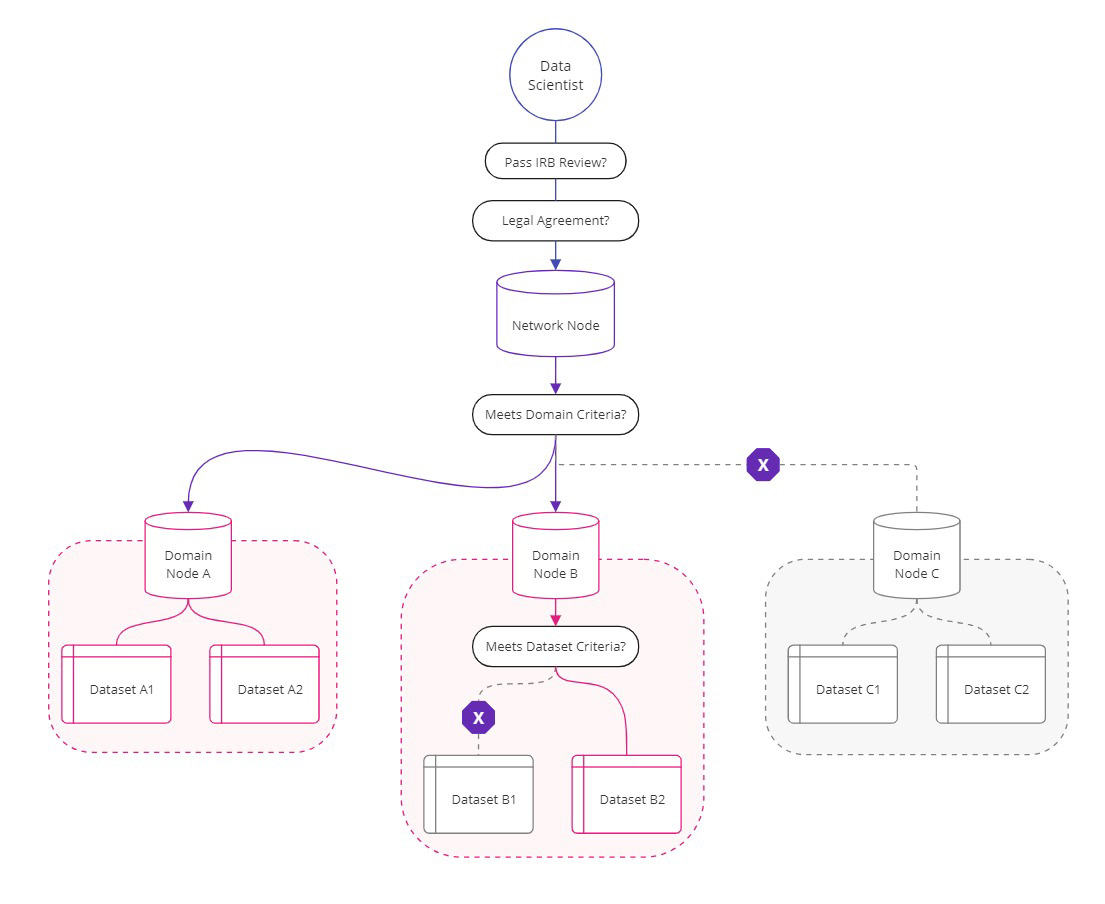
(Image: Mapping FDN network flow in PyGrid 0.7.0, if given permission, network nodes can help triage requests made to domains.)
The Broader Picture
Ultimately, this research reframed how PyGrid approached decentralization— not as a purely technical goal, but as a social architecture of trust. Combining learnings from our Early Access research initiative, we reframed our adoption strategy. If PETs literacy required experimentation then trust required collaborative sense-making. We evolved our partner relationships from that of being service-providers to that of being co-creators, our product from being a platform to being infrastructure, and our pilot efforts from being research-level feats to being deployments of different sandbox spaces so that those in the academic, NGO, or statistic bureau communities could learn, build, and push their own visions of the future for data collaboration. Some examples of pilots informed by this work are:
- an international trade pilot with the UN PET Lab
- an AI Transparency pilot with the Christchurch Call Initiative
- an infrastructure offering to the NSF (U.S. NAIRR Pilot)
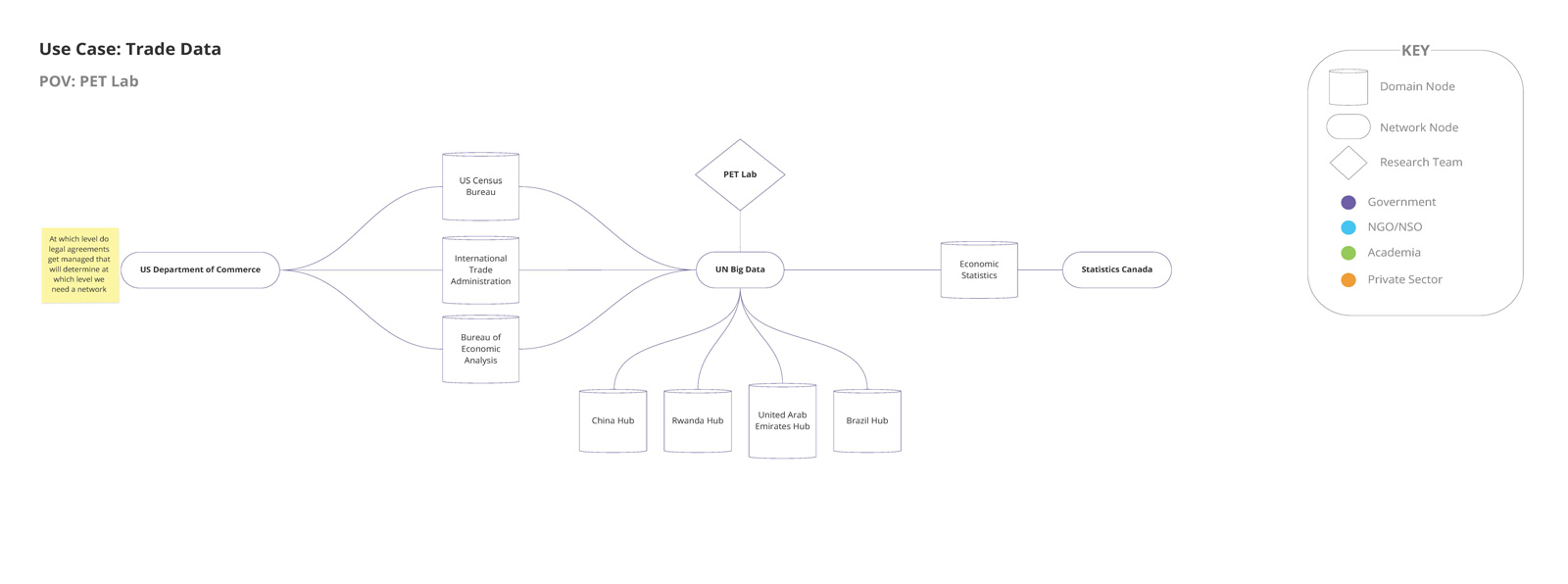
(Image: UN PET Lab Pilot network map)