Summary
As design lead on OpenMined’s decentralized PET stack (PySyft, PyGrid, PyGrid Admin), I started treating information flows—not interfaces or isolated features—as my primary design material.
Across my time at OpenMined I had been working on AI evaluation and cross-institutional research use cases. These use cases by their very nature forced me to view data as a focal point for my designs. By designing with this focal point I began to realize that focusing on the data level (micro) and the information flow (macro) could be a new avenue for design in the age of AI. I began to ask:
What happens if we design from the flow of information and its social context first, and treat UI, APIs, and protocols as ways to shape those flows?
To probe that question, I:
- Mapped how data, models, and decisions move between institutions and roles, not just within a single product.
- Turned these mappings into socio-technical frameworks (impact ladders, logic models, role maps, system evolution diagrams, capability “skill trees”).
- Used those frameworks to redesign our PET stack as a protocol for collaboration and oversight, rather than a standalone product.
I don’t claim this “solves” AI design problems. Instead, I see it as an early example of information-centered design: a practice that could help future product designers reason about AI systems whose behavior extends not just to the screen that mediates them but to the tools that shape the data that feeds them.
Why information flows became my main design material
At OpenMined we created tools for privacy-enhancing technologies (PETs). Our particular focus was on secure enclaves, secure multi-party computation, differential privacy, and remote execution. These tools are often described as a means to “make it safe to share data.” In practice, I kept seeing something subtler:
Organizations weren’t just struggling with data access; they were struggling with who gets to ask what, about whom, under what conditions, and with what visibility.
AI model evaluation, in particular, exposed a gap: PETs could protect data, but they didn’t tell us how questions, models, and accountability should move between labs, regulators, and the public. I realized that many of our hardest product questions were actually questions about information flows:
- Who originates data? Who transforms it? Who consumes the resulting insights?
- What expectations travel with that data as it moves?
- When do those expectations get lost or violated?
As product lead on PyGrid and design lead across tools, I began to treat those flows as the thing to design around. Interfaces, protocols, permission models, and even education efforts became means to shape information flows and their governance, not ends in themselves. That shift is what I think most product designers will need in the age of AI.
Expanding design's scope for context
In more traditional interaction design, “context” often refers to the device (phone, laptop) or physical and social setting (hospital, kitchen) in which a user encounters a product. These framings are well suited to bounded interactions, where the primary design challenge is shaping a moment of use.
In AI systems, however, context begins to look different. Because AI systems operate by transforming and recombining information over time, context can no longer be understood solely at the interface. It must also include the lifecycle of information itself—how data is collected, transformed, interpreted, and acted upon as it moves across people, institutions, and technical systems:
- Who collected the data, and under what promises?
- Who transformed it and how (e.g. into models, metrics, or dashboards)?
- Who relies on those outputs, and who is affected but not represented?
- How do these relationships shift as systems evolve?
This distinction became clear to me when comparing two forms of governance work. In a UN PET Lab pilot on international trade data, I was working primarily with static tabular datasets. The core design challenge was embedding norms and constraints into a fixed data object—defining what could be accessed, by whom, and under what conditions.
AI evaluation, by contrast, exposed a fundamentally different kind of context. Even when evaluation datasets remained static, the systems under scrutiny were not:
- Models would be updated, fine-tuned, and redeployed.
- Evaluation criteria and threat models evolved.
- Stakeholders (e.g. labs, regulators, and civil-society groups) would need to enter and exit the process.
In this setting, designing for “context” meant treating model behavior over time, and the evolving flows of questions, evidence, and accountability around those models, as the primary design objects. Interfaces were no longer just points of access; they became sites where informational relationships had to be surfaced, interpreted, and contested. This reframing led me to ask:
- How might information flows be made visible and negotiable to the people who depend on them?
- What kinds of protocol and UI affordances are needed if ongoing AI evaluation becomes the central design challenge?
The remainder of this case study describes the socio-technical frameworks I adapted in response to these questions, and how they point toward a broader conception of design practice grounded in informational context.
Socio-technical frameworks for designing with information flows
01 Impact Ladder: From abstract vision to concrete flows
I started design work every quarter by aligning myself and leadership on the founder’s (Andrew Trask’s) long-term vision:
“A world where every good question is answered, and nothing else.”
This vision was intentionally broad and crafted to steer general organization alignment and marketing. To make it actionable, I then led impact ladder workshops, specifically I adapted IDEO’s human-centered design toolkit, and broke down this larger vision into smaller impacts that served as rungs by which we could build to the larger vision.
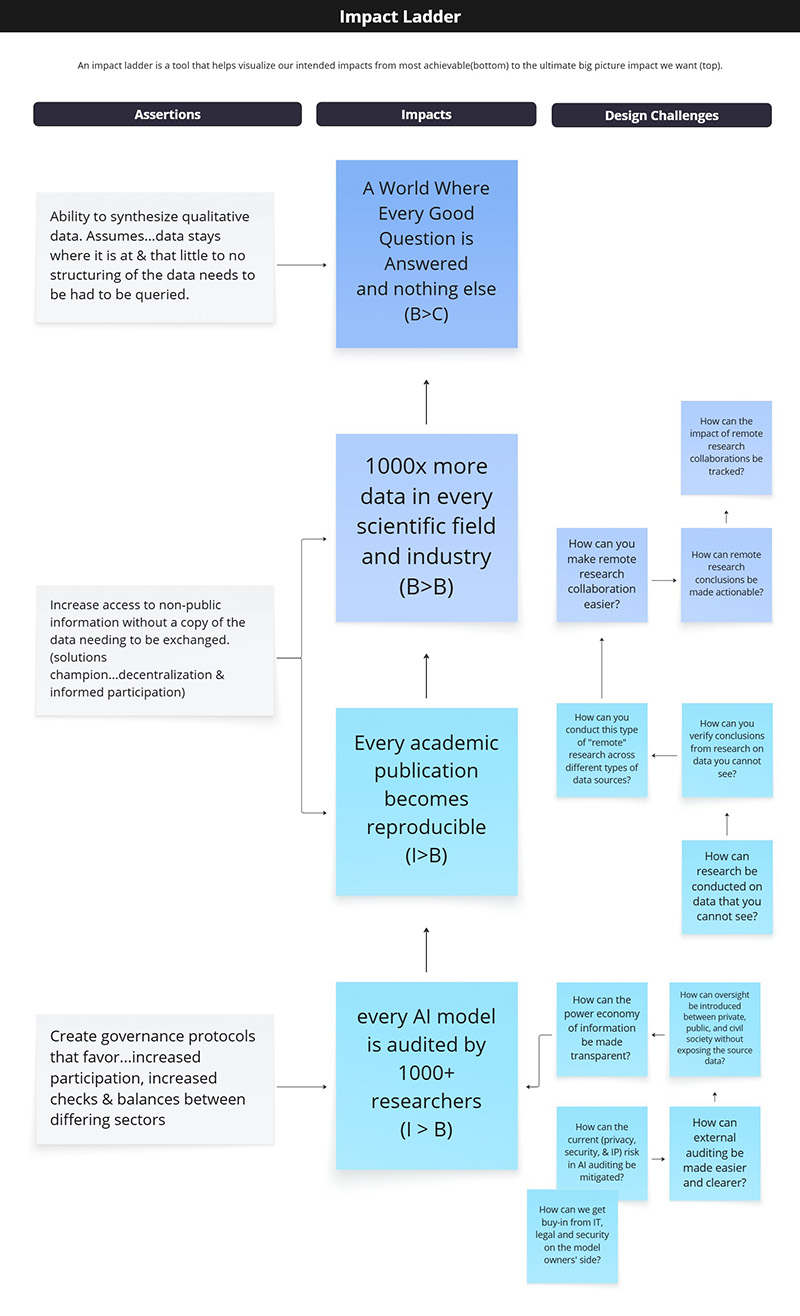
Image: Impact ladder to kick off OpenMined work at the end of 2023
This ladder forced us to specify: (1) which information relationships we were actually trying to change (e.g., between model owners and external auditors) and (2) what flows would indicate progress (e.g., more audits conducted under safe constraints, more cross-org research on sensitive data).
For future design efforts, it formulated design challenges at the org’s mission level instead of the feature level. For example, instead of beginning design efforts with “How might we showcase model distinctions in a model card (a feature level inquiry)?”, design efforts with our teams first explored top-level questions such as “How can the current (privacy, security, & IP) risk in AI auditing be mitigated?”. This provided a clearer lens around who to conduct qualitative studies with and what literary research was necessary to begin with before diving into code.
Future Application
For future design, a generalizable question here that this form of impact ladder works towards mitigating is:
If the product vision changes, could we as a product team articulate how information would need to move differently between people, systems, and institutions to make that vision real?
As a product team can we articulate how our defined design challenges tie to the org's social impact?
02 Logic Model: Tying design challenges to paradigm shifts
Taking the lowest run within the impact ladder, I would then adapt a logic model to make impact operational. Instead of a typical chain that specifies Impact → Outcomes → Outputs → Inputs, I used a socio-technical framing that described desired paradigm shifts (e.g., model owners seeing audits as safe, not as automatic IP risk) as explicit outcomes and listed outputs as proof points and failure modes, as opposed to more traditional engagement metrics.
For example, if we take the design challenge:
“How can the current (privacy, security, & IP) risk in AI auditing be mitigated?”
Proof points might include:
“# of successful AI audit pilots with main AI labs where the pilots prove progressive levels of safety. For example: evaluation on sample model, legacy model, or reproducing a previous result.”
Through iteration, my logic models took the form of: Social Impact → Top Design Challenge → Intermediate Challenges → Starter Challenges → Proof Points → Product Focuses.
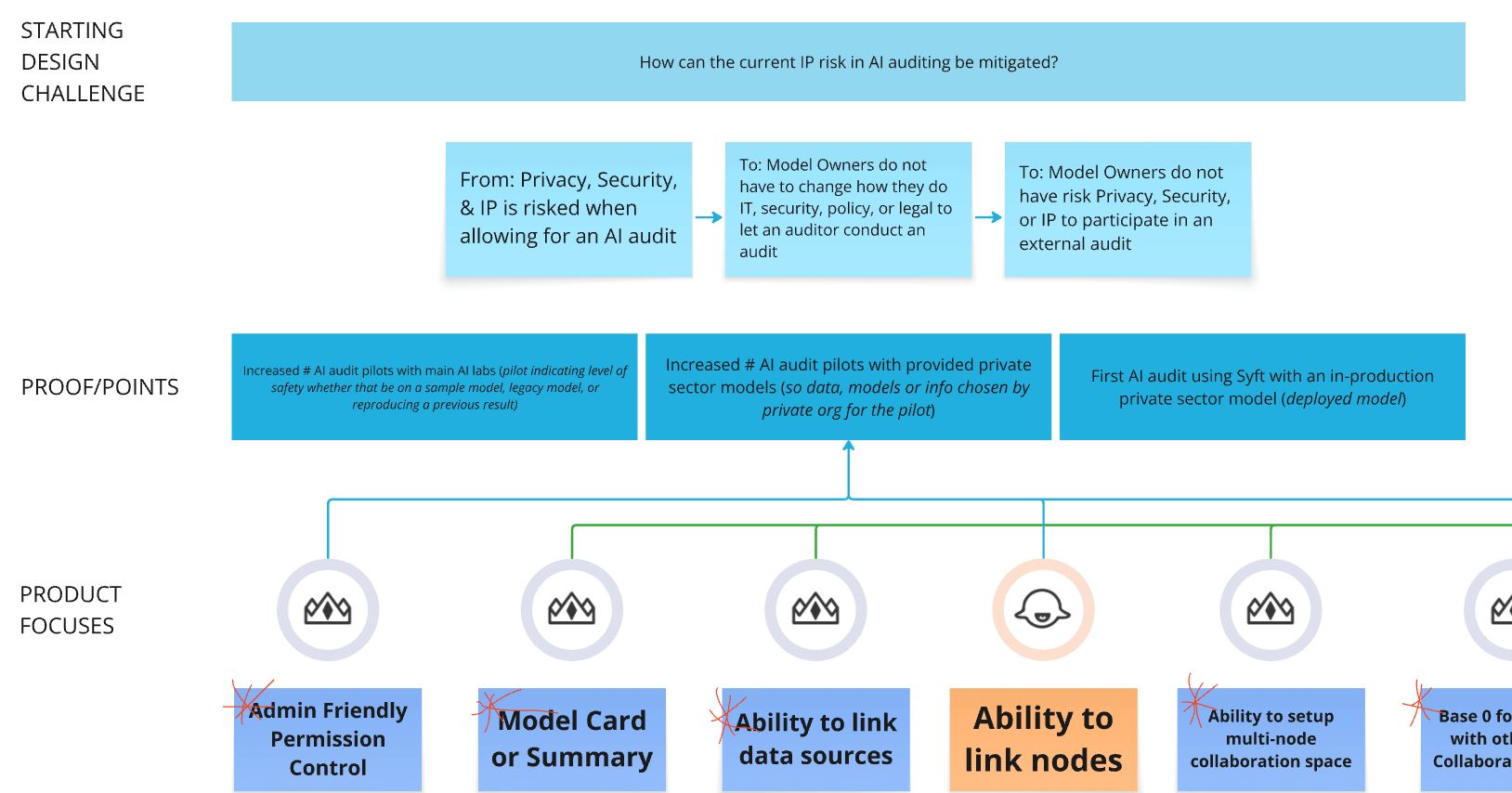
Image: Zoomed in slice of 2023 logic model, highlighting paradigm shifts tied proof points and product builds.
By linking our top-level design challenges to actor paradigm shifts and more socially focused proof-points, I found logic models to be one of the most effective methods for bridging our organization's social aspirations with the more concrete efforts being proposed by our partner, education, and engineering teams. From these quarterly logic models, our teams were able to see how our builds contributed to the larger picture and organizationally we began to see opportunities around how we could spend efforts towards non-conventional initiatives such as PET’s education in government policy spaces.
Future Application
For future product designers, this kind of framing could be a way to ask:
Which paradigms shifts can be supported through the capabilities of our product? Which lie outside of our domain (e.g. spaces such as legal and policy)? Are there bridges of understanding that need to be made in between?
03 Role Mapping: From legal/privacy concepts to product roles
Moving beyond top-level planning, I then began to transition learnings from our qualitative studies into more concrete product principles. One discovery made through partner workshops was a mismatch between our platform roles and their day to day roles.
Our roles (e.g. data subject, data owner, data scientist) were based on a data science context and in doing so assumed neat distinctions between owning and analyzing data. In practice, many actors both owned and analyzed data, switching roles based on context.
While it was important to frame a participant’s relationship to data internally, externally across our tools it became increasingly apparent that we needed to empower communities by giving them the controls to encode their own understood roles within the system.
Through role-mapping sessions with leadership, we refined our internal product roles to better reflect a user’s relationship to the data (e.g. data subjects, data stewards, collectives, service providers, etc.) which helped us when discussing PETs capabilities and features. However for our system’s external roles, I proposed a more agnostic, participation-focused role system: owners, admins, moderators/stakeholders, contributors, subscribers, each defined by how they participate in the system and how they intend to participate with the data.

Image: Zoomed in slice of role-mapping diagram which defined differences between internal privacy-based roles and external system participation roles.
This exercise of refining internal roles based on our privacy theories versus defining external agnostic roles based on system participation raised questions such as:
- What is the smallest set of participation patterns that still lets different communities encode their own norms?
- How can we design roles so that people can see themselves (as subjects, stewards, auditors, etc.) without hardcoding one governance regime?
Future Application
For future designers working in AI, this suggests a pattern:
As our communication loops become more dynamic, as information transitions to a more real-time state, how can we design permission models and role systems that allow for shifts based on context?
04 System Evolution & Capability Tree: Exploring future architectures
Continuing work from the more abstract to the more concrete, I began translating proof points into future state system-level maps and skill tree diagrams. The system-level maps were structured with the data owner at one end and the data analyzer at the other. Formed in seven levels, each map charted how a remote interaction between the two could possibly be supported with a combination of PETs and governance features. With each progressive level the nuance and depth behind what rulesets could be enforced around data use as well as what types of questions could be asked deepened. These system maps acted, as a base by which to build pilot proposals off of, as each level corresponded to a pilot proof point.
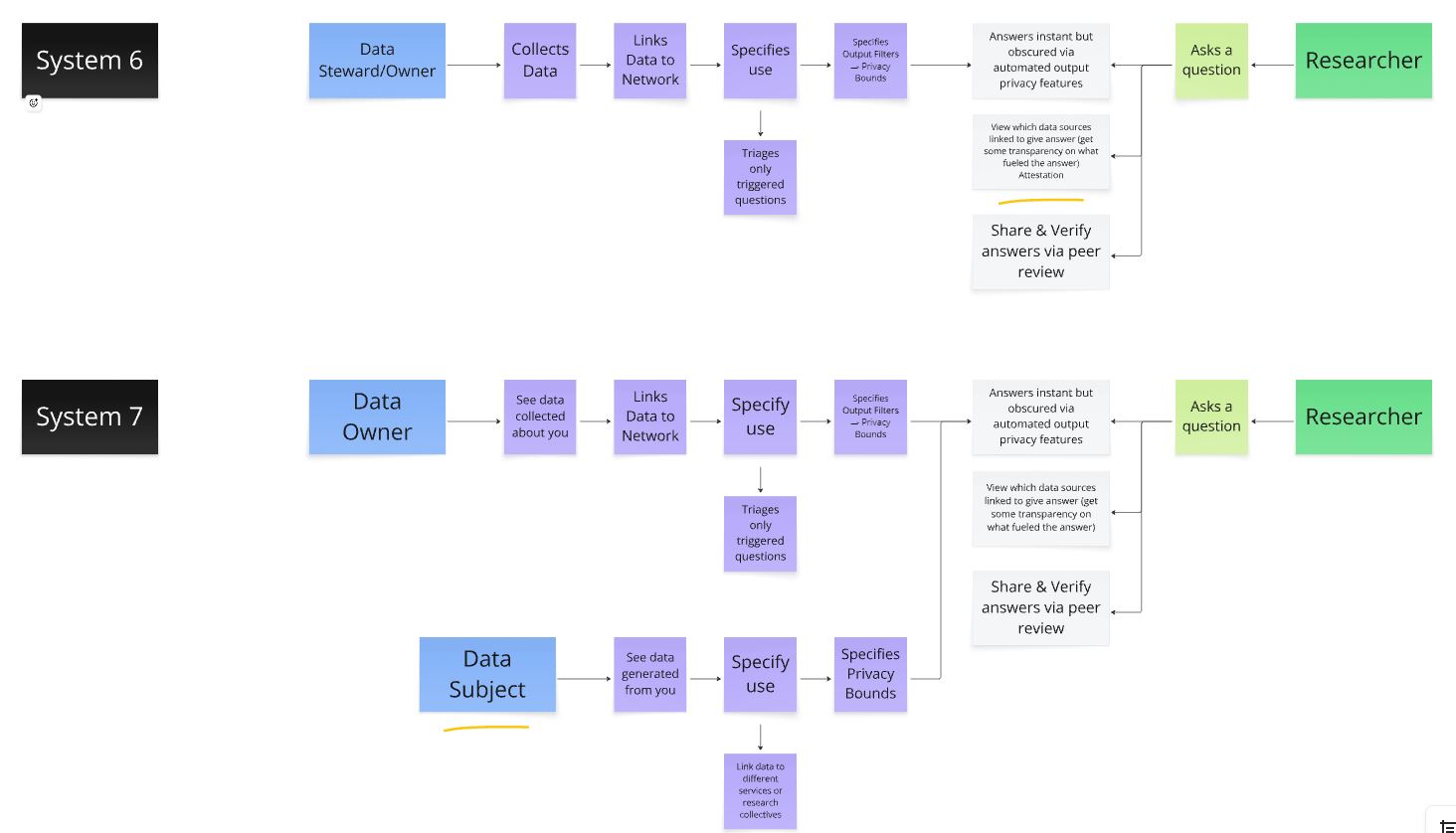
Image: Zoomed in slice of system-level maps where each level indicated new modes of enforcing privacy expectations and new depths to remote data query.
While system-level maps helped us visualize and iterate our ideas around how to test general governance flows for pilots, skill tree diagrams helped us plot and iterate on feature builds for our product releases. Incorporating elements common to RPG games such as themed clusters, nodes, and unlock dependencies; the skill tree I built and iterated with engineering on for OpenMined clustered tool capabilities around pillars of PET primitives and structured transparency (e.g. input/output privacy, input/output verification, flow governance) and tied them to our main system objects (nodes, data subjects, datasets, models, users, methods/functions).
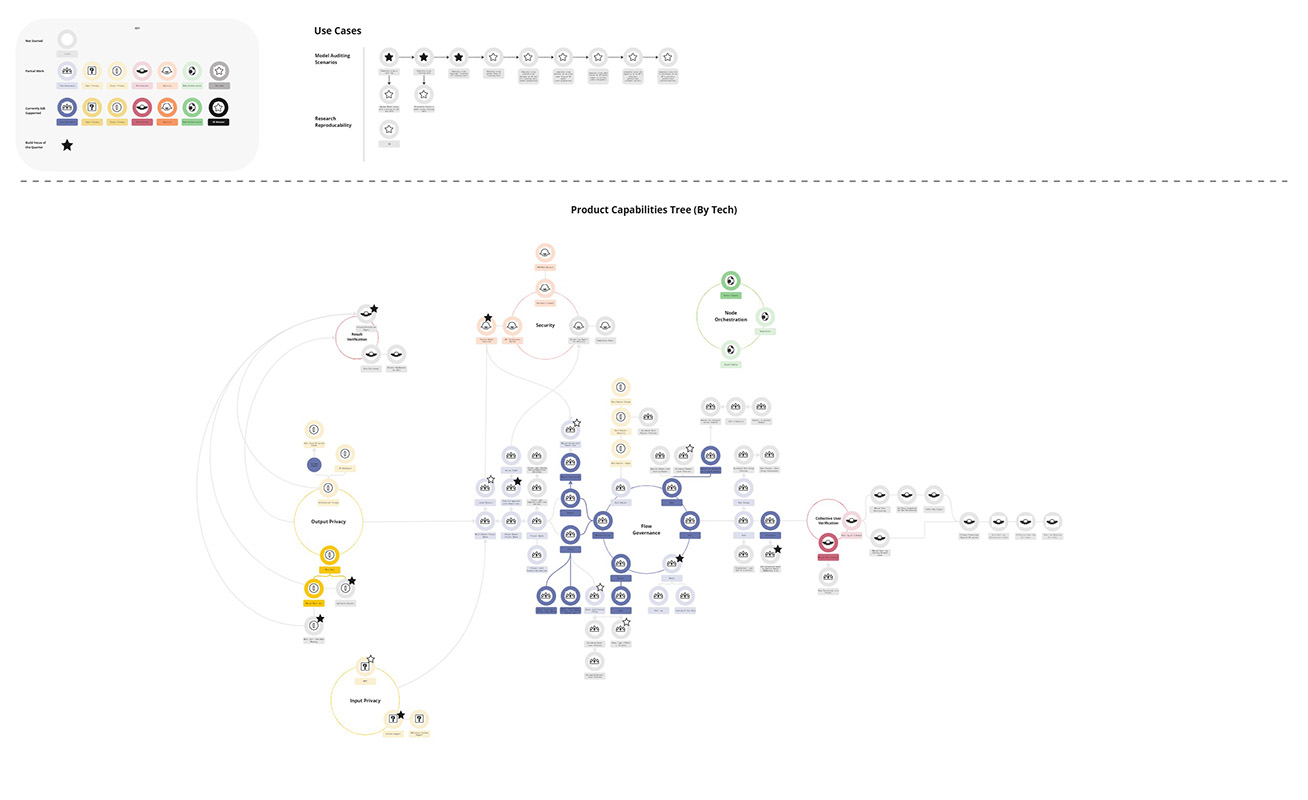
Image: Full view of our tech skill tree which mapped technical capabilities to governance features.

Image: Skill tree "key", node colorization, cluster, and icon were tied to PETs and structured transparency primitives.
By viewing which features supported which pillars of structured transparency and by viewing how capabilities tied to system objects, we were better able to visualize how our API logic and tooling may support, leave gaps, or affect data agency and context. For example, brainstorming what might need to be explored to support two organizations in jointly answering a question about a model under strict privacy constraints, we were able to see through the skill tree that we had not yet supported a form of input privacy and therefore had no feature-set to test semi-trust collaborations across joins.
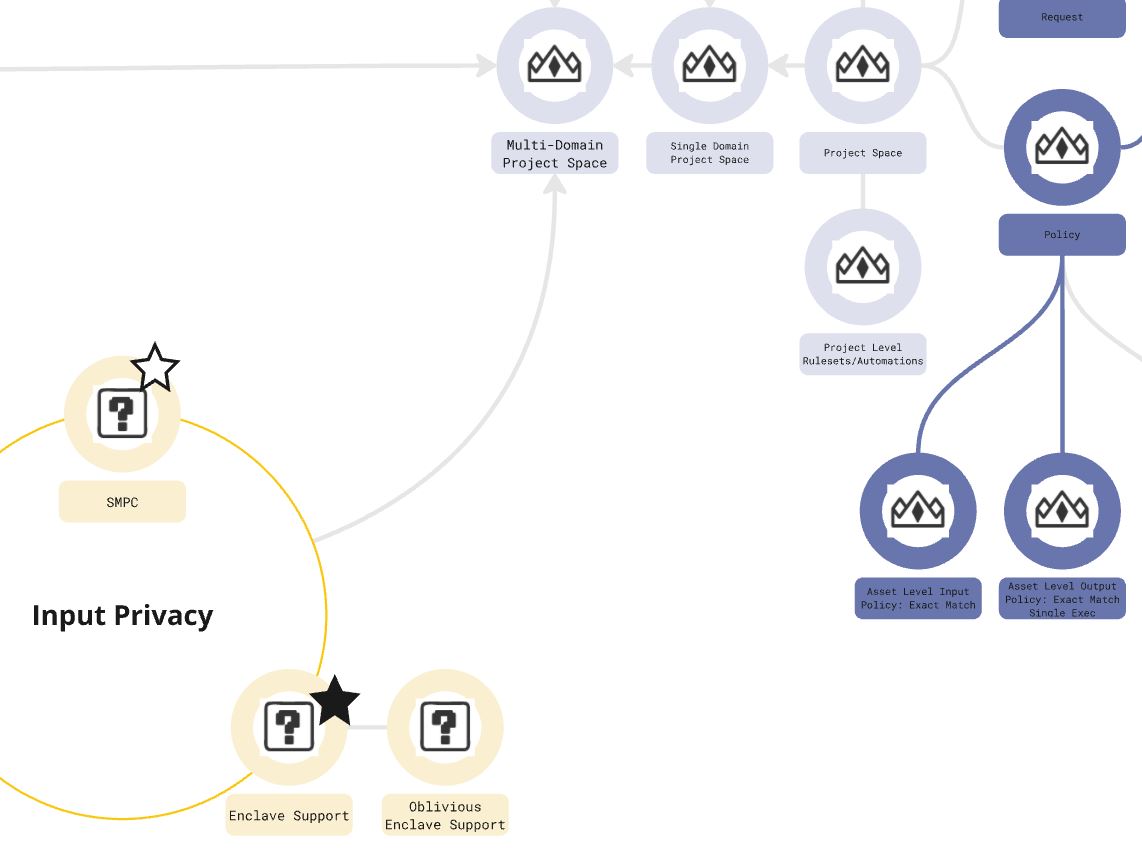
Image: Zoomed in section of skill tree that shows how input privacy capabilities link to project objects.
Ultimately, using these tools in combination helped our teams ask:
- What kinds of information flows are conceivable if we combine PETs in certain ways?
- Which capabilities are prerequisites for more ambitious governance scenarios?
Future Application
For design, this could suggest another transferable practice:
How might you treat your technical stack as a capability space and explicitly map: primitives → possible flows → governance possibilities?
What kinds of diagrams would help your team envision the futures your system is testing against or building towards?
How this changed what we built
These frameworks were not just static diagrams or slides; they were negotiable and iterative artifacts that concretely shaped how we thought about building. Our logic model combined with our skill tree helped us see that we needed to build a space for context if we were to support AI evaluation use cases. We shifted focus from one-to-one data collaborations (a single researcher, a single static dataset) toward project spaces where multiple organizations could join data, models, and context for AI auditing. We began to design collaboration workflows where: model owners could define sandbox conditions, data owners could express constraints on how their data is joined or queried, and auditors and regulators had clear, bounded ways to probe models under PET constraints.
Throughout the process from planning to execution these artifacts oriented us with guiding questions:
- What information flows are we enabling or blocking here?
- Whose perspective is visible in this flow, and who is invisible?
- Which combinations of PETs meaningfully change those flows, and which are fragmented feature sets?
Every time my team would hit these questions we would then pull up one of these artifacts and talk through how we might move forward. This practice kept my team not only mission aligned, but also kept us nimble going between micro and macro thinking— to continually question how our decisions at the interface or API level matched up to the bigger picture of social impact (in this case increased AI evaluation).
What this suggests for future product designers
Looking back, I see my time as a design lead at OpenMined less as “a series of designs I led” and more as an early experiment into what product design might become in the age of AI. Although our work was primarily centered on AI evaluation, I believe these adapted methods with an information-centered frame could benefit and perhaps if developed further fundamentally change design's role in AI product influence.
Instead of ending with prescriptive advice, I find it more honest to frame what I learned as questions I think other designers might also benefit from asking:
- Designing from information flows, not just user journeys.
- What are the key information flows in and around your product, and how would your design change if you treated those flows—not screens or tasks—as your primary canvas?
- Where in those flows are expectations created, preserved, broken, or lost?
- Using socio-technical frameworks as design tools.
- What impact ladders, logic models, role maps, or capability diagrams would make your assumptions about people, power, and information explicit enough to critique?
- How might you keep those artifacts alive as part of the design process, rather than filing them away as strategy documents?
- Where do tears between big picture strategy and nuanced technical decisions occur? How can the tools we have as designers bridge those gaps internally?
- Starting from roles in relation to information.
- What is the main object being interacted with in your product, system, ecosystem?
- How would your description of roles change when describing a participant’s: interaction with that object, agency towards that object, impact by that object?
- Measuring proof points and failure modes, not just engagement.
- Beyond clicks and adoption, what would count as a proof point that your system is delivering on its product promise/contributing toward the org mission?
- How might your product or system create negative or the exact opposite effects than intended? (Failure Modes)
- How might those proof points or failure modes change the way you design features and prioritize work?
- What might you need to learn from communities to test against those proof points?
- How might you check-in with communities to test against those failure modes?
- Using interfaces and protocol design as hypotheses.
- What implicit theory about people and institutions is baked into your current roles, flows, and policies?
- How might you design your product so that you can tell when that theory is wrong and iterate on it?
Questions I’d like to pursue
The time I spent at OpenMined left me with questions that I think could benefit from academic exploration. Specifically, I’m curious about furthering:
-
Pedagogy:
How might we further develop and teach information-centered design as a core skill for product designers, alongside interaction and visual design?
-
Methodology:
What combinations of mapping and prototyping best reveal hidden assumptions about power and information dynamics in AI products? How can the role of a designer in these products help track performance to social impact using these tools?
-
Governance & standards:
When should internal design frameworks evolve into shared standards or regulatory tools, and when are they more useful as experimental artifacts?
-
Tools & infrastructure:
How might future information-centered design support new substrates for agency, particularly through bridging semantic AI and local-first computing?
My work at OpenMined has been one attempt to answer these questions in the context of AI auditing and PETs. I see this as a starting point for a broader research agenda on how product designers can responsibly shape the information flows that AI systems depend on, and how we might empower the next generation of designers to question, inform, and build for the communities those systems impact.